- 移动端


深圳市艾斯基因科技有限公司
4 年
手机商铺
- NaN
- 0
- 0
- 1
- 0





公司新闻/正文
Nature medicine | 大规模PBMC单细胞转录组揭秘循环免疫细胞的“炎症地图”—可解释机器学习模型
200 人阅读发布时间:2026-01-19 14:51
炎症是机体应对环境挑战的重要免疫应答,其生物学过程涉及细胞激活、信号传递与免疫细胞募集,旨在清除病原体并维持稳态。但炎症的失调也与心血管疾病、自身免疫病、感染性疾病和癌症等密切相关,使其成为重要的治疗靶点。然而,目前对炎症状态下免疫细胞在单细胞层面的系统功能变化及其在疾病中的作用仍缺乏全面解析。单细胞转录组测序(scRNA-seq)作为从细胞水平研究病理条件下细胞状态和基因表达程序的重要手段,将有助于更全面理解炎症在急慢性疾病的作用。
近期,Nature medicine刊发了题为“Interpretable inflammation landscape of circulating immune cells“的研究论文。该研究利用scRNS-seq技术,对来自1047名患者(涵盖19种疾病)的650多万个外周血单个核细胞(PBMSs)进行分析,构建了一个全面的循环免疫细胞炎症图谱。此外,通过结合无监督与可解释的机器学习算法,该研究构建了炎症相关的基因表达模型,开发了可应用于临床的炎症PBMCs分类框架,为基于循环免疫细胞的炎症诊疗提供了重要参考。研究主要聚焦了以下三个科学问题:
1. 在疾病相关的炎症中,外周血免疫细胞的细胞状态是如何发生功能特化的?
2. 哪些关键基因表达特征可系统揭示免疫细胞活化、迁移、毒性应答核抗原呈递等炎症相关功能?
3. 能否基于PBMCs的单细胞转录组特征,构建可用于炎症相关疾病精准诊疗的分类模型?
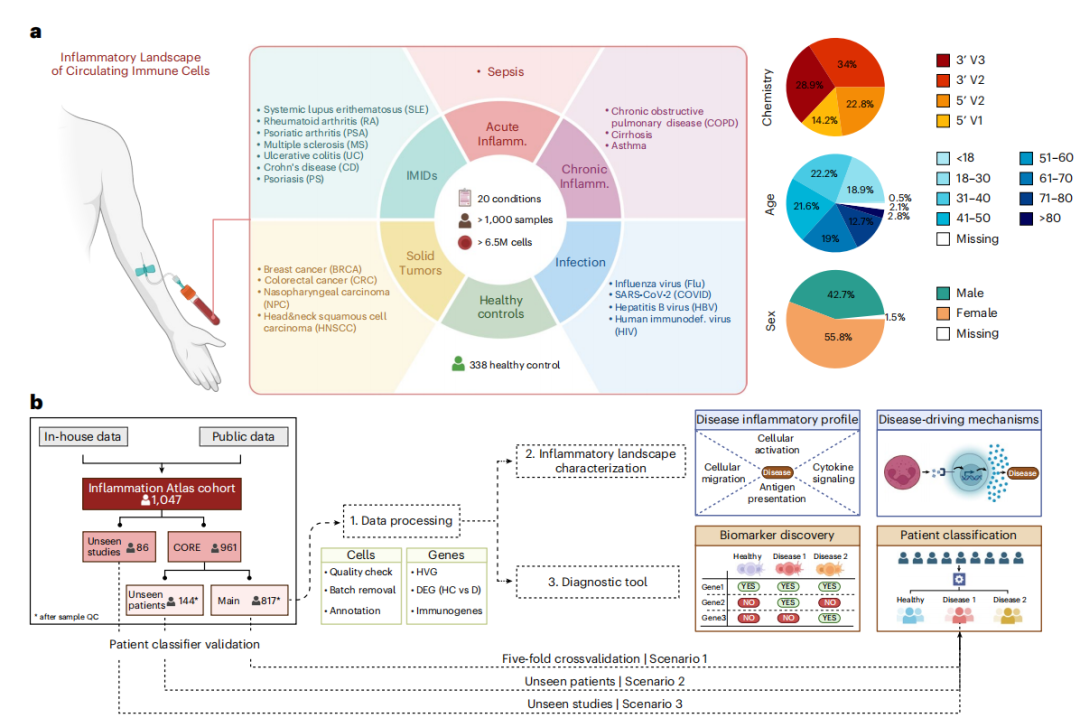
图1 实验设计和研究思路概览
英文标题:Interpretable inflammation landscape of circulating immune cells
中文标题:可解释的循环免疫细胞炎症图谱
发表时间:2026年1月12日
发表期刊:Nature Medicine
技术方案:PBMC单细胞转录组测序(艾斯基因重要产品技术)
样本类型
1047名患者和338例正常对照。患者组涉及19种疾病,大致分为五个组别:(1)免疫介导的炎症性疾病(IMIDs,n=7),共7种;(2)急性疾病(n=1),即败血症;(3)慢性炎症性疾病(n=3),共3种;(4)感染性疾病(n=4),共4种;(5)实体肿瘤(n=4),共4类。
主要研究结果
1. 绘制炎症相关的PBMCs免疫细胞图谱
研究团队在考虑临床诊断指标、性别和年龄的基础上,采用基于概率模型的scVI和scANVI算法对多样本单细胞数据进行整合分析,成功构建了超650万个PMBCs的免疫细胞图谱。第一层次的细胞注释共鉴定15种细胞类型(Level 1),包括B细胞、浆细胞和单核细胞等。第二层次的细胞注释共鉴定了64个免疫细胞亚群(Level 2)。细胞组分分析显示,不同疾病呈现明显不同的免疫细胞分布特征差异,并且与以往报道基本一致。
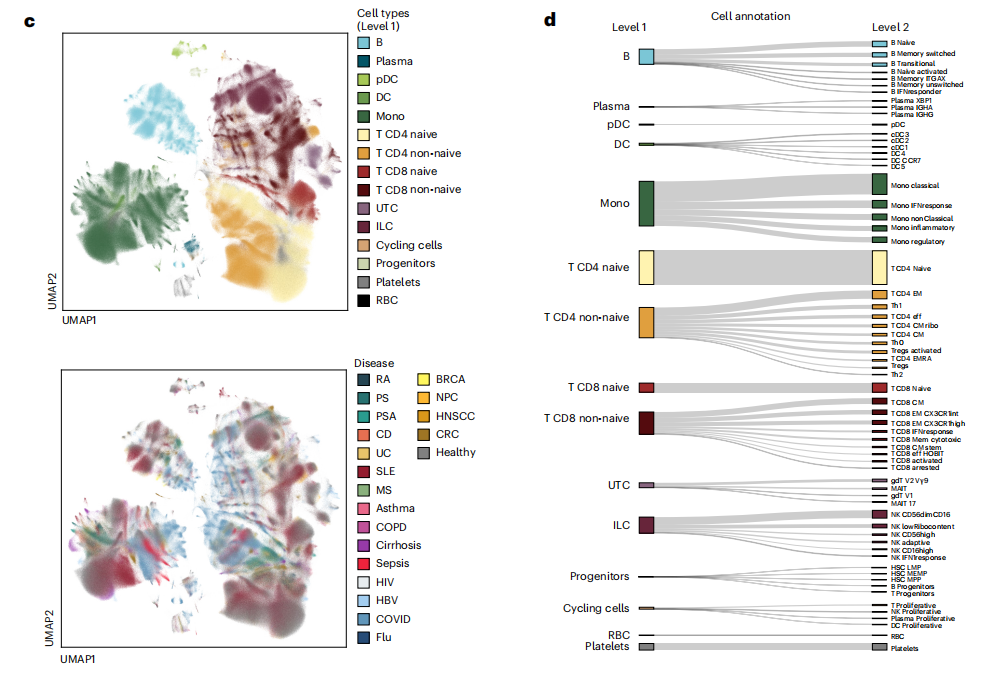
图2 细胞注释结果
2.不同疾病和细胞类型的炎症特征
在得到细胞注释结果后,研究者通过基因特征和调控网络分析来识别驱动炎症发生的机制。他们先将炎症相关分子分为21个基因特征,包括免疫细胞粘附、激活、迁移、抗原呈递及细胞因子信号等过程。为了更精确反映循环免疫细胞的炎症状态,研究者利用Spectra工具优化,得到119个细胞类型特异性因子。接着,对经过scANVI校正的单细胞基因表达数据,采用单变量线性模型(ULM)分析,为每个特征组计算炎症特征活性评分。最后,通过线性混合效应模型(LMEM)比较疾病与健康样本,识别疾病特异性的炎症特征改变。
分析结果表明,与健康供体相比,各类疾病普遍存在免疫炎症特征活性增强的趋势(图3a)。其中,在免疫介导炎症性疾病,即IMIDs中,表现出黏附分子、TNF/NFκB信号和抗原呈递特征上调,而I/II型干扰素特征普遍下调的共性模式,但非初始CD8 T细胞(non-naive CD8 T cells)例外,提示存在细胞类型特异性机制。不同疾病也展现出独特特征,例如系统性红斑狼疮几乎所有细胞IFN诱导特征上调,多发性硬化症则趋化因子受体活性升高,脓毒症呈现TNF信号在CD8 T细胞的特异性激活。此外,T滤泡辅助细胞特征仅在类风湿关节炎等少数疾病中富集,揭示了特定T细胞亚群在不同疾病中的差异化作用。
临床上,干扰素特征已被作为自身免疫病的关键生物标志物之一,但其具体的细胞来源不明,限制了精准靶向治疗。前期结果发现,干扰素特征仅在非初始CD8 T细胞中异常上调,因此研究者将其作为重点研究对象,探寻驱动该特征的具体细胞亚群和基因。深入分析发现,(1)FGFBP2和GZMB在特定的效应记忆CD8 T细胞亚型的表达水平较高,是驱动干扰素特征的两个基因。FGFBP2和GZMB的激活在血液循环阶段(即浸润组织前)就已发生,说明可以早期血液检测候选生物标志物。(2)利用基因调控网络分析,发现参与干扰素特征的上游关键转录因子STAT1和SP1(图3e)。它们在细胞特异性表达模式如下表:
|
疾病 |
STAT1 |
SPI |
|
系统性红斑狼疮 |
在非经典单核细胞、cDC2中升高 |
在炎性与调节性单核细胞、效应/活化CD8 T、NK细胞中升高 |
|
流感 |
在IFN-应答CD8 T细胞中显著升高 |
- |
|
肝硬化 |
- |
在IFN-应答单核细胞中特异性升高 |
|
头颈鳞癌 |
- |
在非经典单核细胞中升高(该群细胞具促肿瘤特性) |
(3)在17号系统性红斑狼疮(SLE17)并经历疾病急性加重的患者(Flare组)中,STAT1活性在患者复发期间升高,尤其在CD8 T细胞内,而SP1活性在无复发时在髓系细胞群体中更为突出(图3f)。
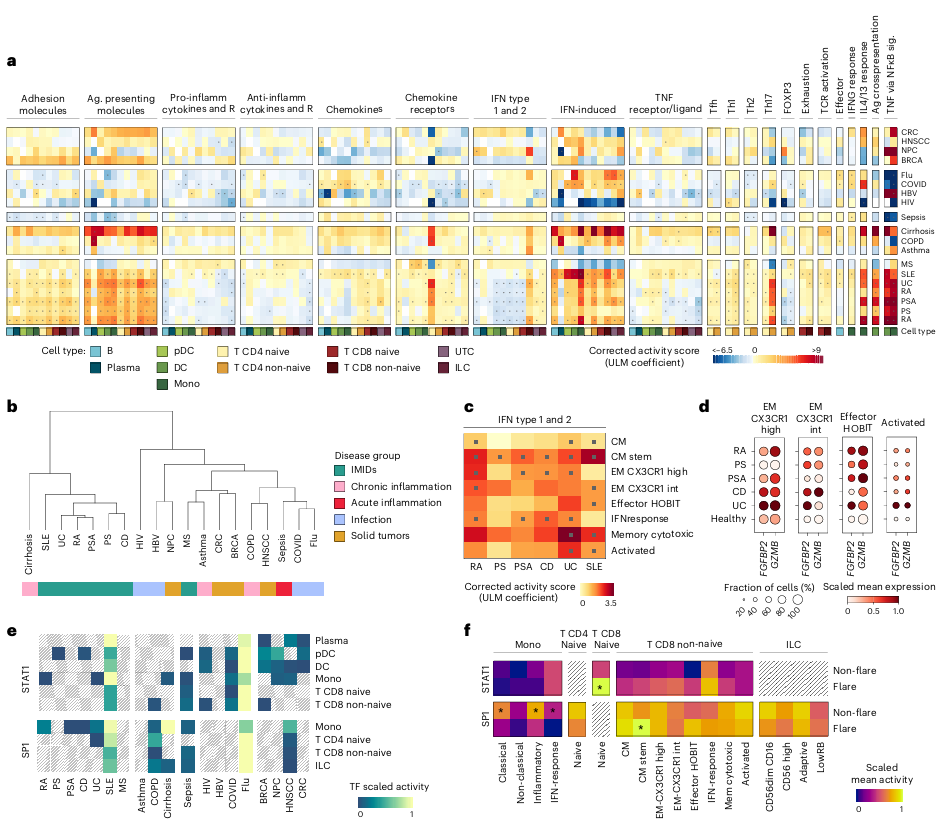
图3 跨细胞类型与疾病的炎症相关特征
3.利用可解释机器学习建模实现细胞分类和疾病来源追溯
常规的线性模型或差异表达分析可能仅聚焦有限的基因,因此,研究者采用一种名为梯度提升决策树的可解释机器学习模型(GBDTs),从细胞的基因表达数据中,将细胞分类到其对应的疾病来源,并借助事后解释方法完成对重要性基因的筛选。
具体而言,研究者对每一细胞类型(Leve1)独立训练了分类模型。与未矫正相比,经scANVI校正后的基因表达谱,该分类流程在独立测试样本中表现优异,平衡准确率(BAS)与加权F1值(WF1)分别达到0.87与0.90。该模型在不同细胞类型间性能稳定,在低丰度细胞群体中略有降低,但依然保持良好表现。值得注意的是,模型在部分疾病分类中出现误差,如重症流感样本被误判为新冠肺炎。进一步分析发现,重症流感与重症新冠肺炎病例在免疫特征上高度相似,经样本水平聚类验证,表明二者共享类似的炎症特征。此外,模型在区分不同性别来源的细胞时未表现出性能差异,说明其具有一定鲁棒性。
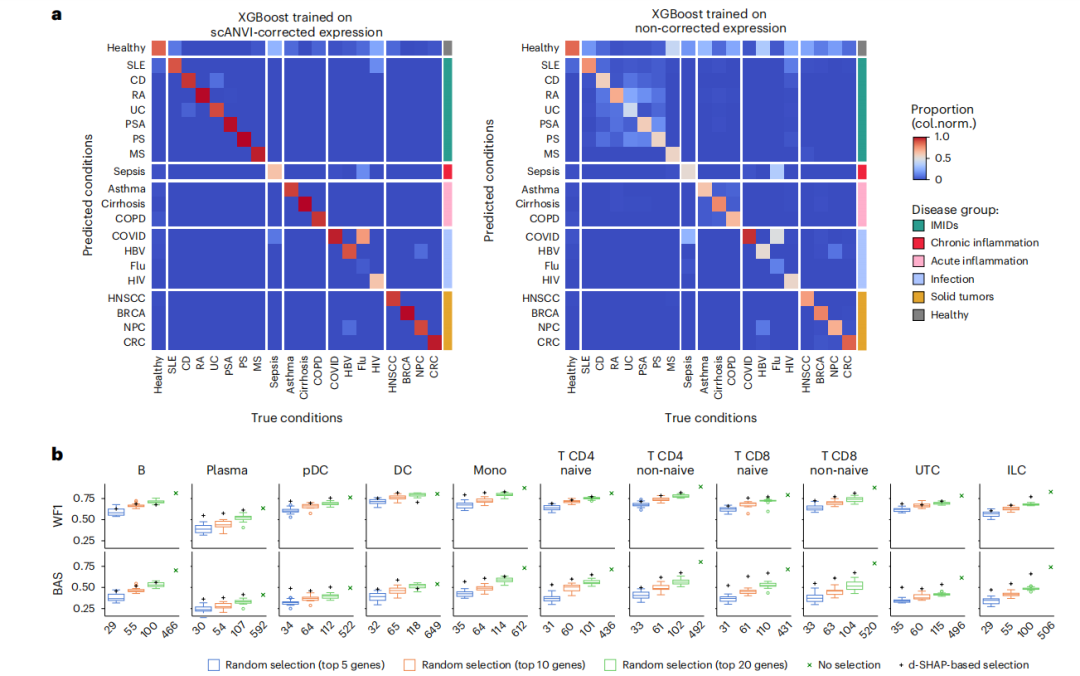
图4 基于可解释机器学习的功能基因挖掘
进一步,研究者通过梯度提升决策树与沙普利可加性解释(SHAP)可解释性分析相结合,构建了一套基于基因-疾病区分能力的排序体系(即图中的d-SHAP得分值,d-SHAP值高的基因,即对该疾病贡献最大、最具判别力的关键基因),在排除研究批次效应干扰后,系统识别出具有细胞类型特异性的疾病相关基因。该分析方法非常有效,不仅验证了已知标志物,还发现CYBA基因在单核细胞中呈现组织特异性表达模式(图5c):高表达与肠道炎症性疾病相关,低表达则关联皮肤炎症性疾病,提示其可能通过调节活性氧生成在不同屏障组织中发挥差异化的免疫调节作用。同时,在慢性呼吸道疾病中,IFITM1在CD4非初始T细胞和固有淋巴细胞中的表达水平可区分慢性阻塞性肺病(COPD)与哮喘,高表达倾向于慢阻肺,表明其可能与慢性炎症下淋巴细胞的肺部聚集有关(图5d)。
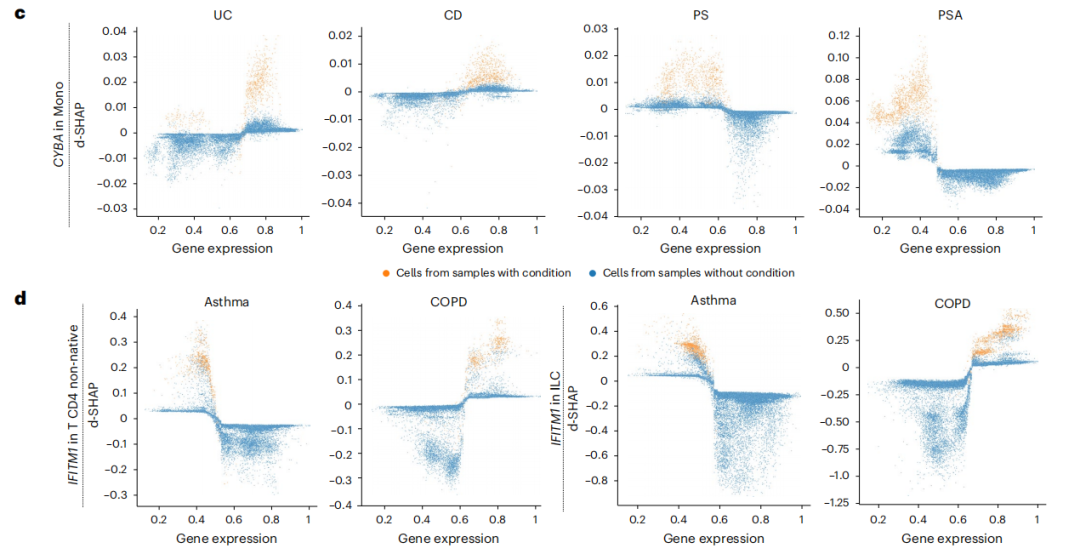
图5 基于d-SHAP的基因-疾病区分模型
4.利用参考图谱对患者进行分类
在实现基于细胞精准分类疾病的模型后,研究者接着开发一种对患者疾病起源进行分类的分析框架。旨在将单细胞参考图谱转化为可应用于炎症性疾病精准诊断的通用分类工具。该框架的具体流程如下:1)统一嵌入空间的构建:利用scANVI将参考数据集和查询数据集的单细胞表达谱映射到同一空间,同时将参考数据集的细胞类型注释迁移至查询数据集,实现跨数据集的语义对齐。2)针对患者的特征工程:对每个患者,按细胞类型计算其伪批量嵌入特征:即在潜空间中,对该患者某类细胞的所有细胞嵌入向量取均值向量,形成细胞类型级别的特征剖面,从而实现从单细胞到患者级的特征聚合。3)分层分类与决策集成:为每一种细胞类型单独训练一个梯度提升决策树分类器,输入为该类细胞的伪批量嵌入特征,输出为疾病标签。同时,汇总每个患者所有细胞类型分类器的预测结果,通过多数投票机制确定最终疾病诊断,以提升模型的鲁棒性。4)三层递进式验证框架:研究还创新性地设计了三种复杂度递增的验证场景(包括内部交叉验证、同研究新患者及跨研究新患者),以系统性评估模型在不同数据整合挑战下的表现:
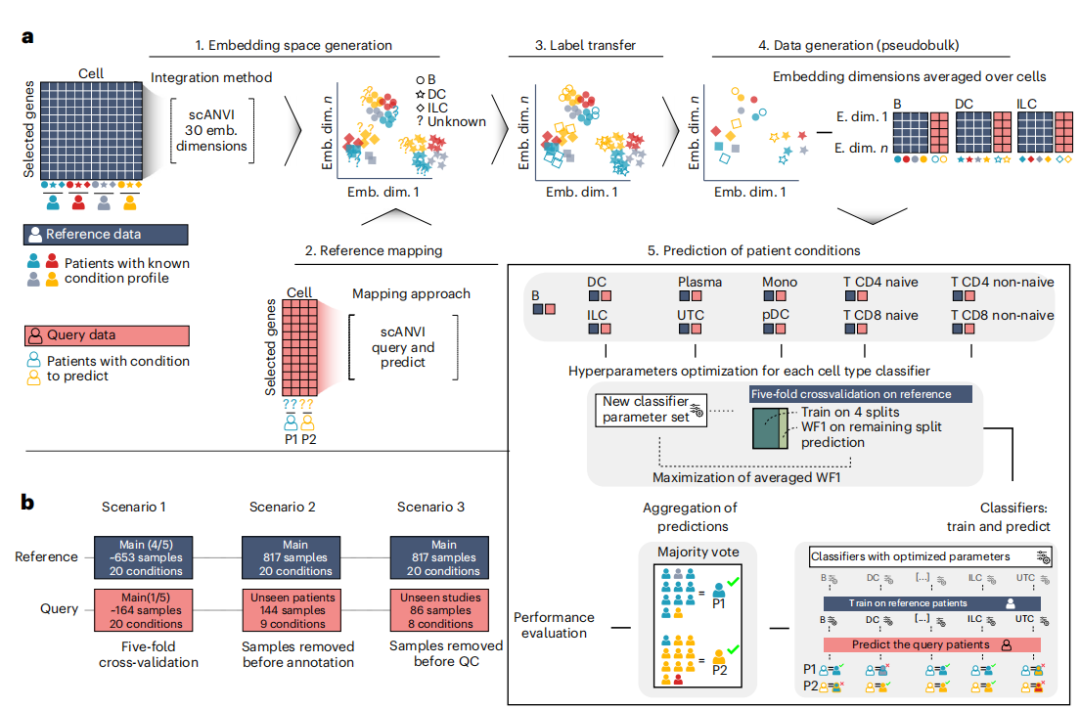
图6 利用参考图谱对患者进行分类的计算框架
该计算框架在前两个场景中表现优异,加权F1分别达0.90±0.03和0.98,但在场景三中性能显著下降(图7i-k),表明跨研究的批次效应是模型泛化的主要障碍。进一步通过数据标准化与中心化处理(仅纳入同中心、同技术的标准化数据重新整合),模型在场景三中的性能显著提升,证明该框架在控制技术变量后具备临床转化潜力。总的来说,尽管利用循环免疫细胞可用于建立炎症性疾病的通用分类器,但本研究使用的数据规模仍较小,未来需要收集更大规模数据来提升模型性能。
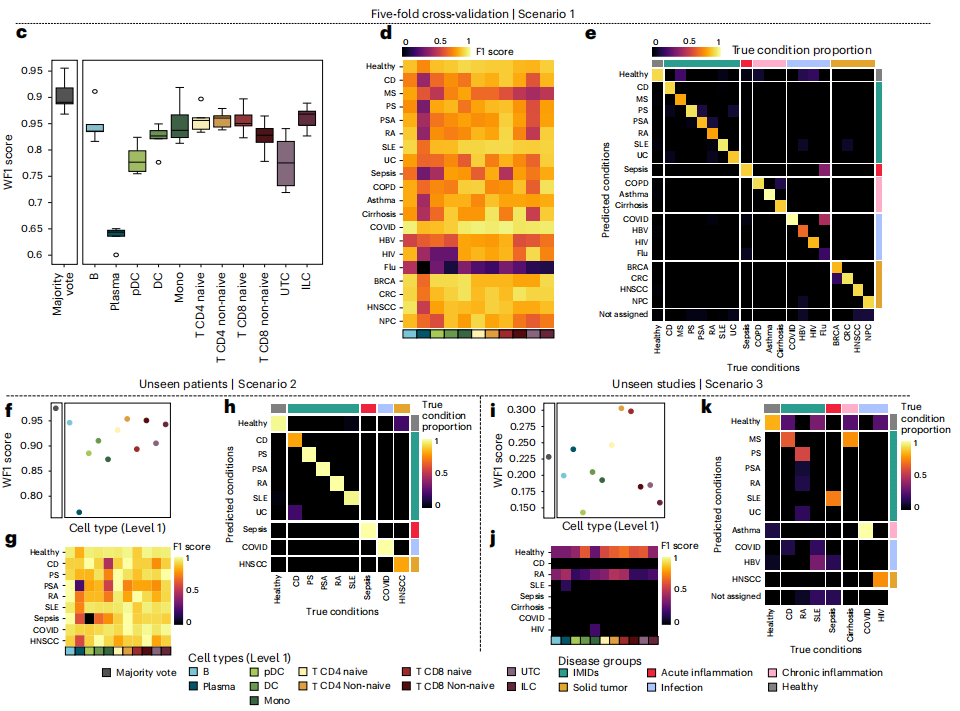
图7 患者分类计算框架的性能评估
为进一步评估scANVI(基于变分自编码器类方法)在患者分类任务中的性能,研究者将scANVI与其他计算框架,如Harmony/Symphony、scGen及scPoli在不同超参数配置下进行比较。结果显示,在相同研究来源的新患者分类场景中,所有方法均保持较高性能;然而,在跨研究来源的新数据集分类场景中,所有方法的预测性能均出现显著下降,其中线性方法Harmony表现最佳,其平衡准确率(BAS)与加权F1值分别为0.24和0.47(图8d-e)。这表明,尽管scANVI1具有更强的表示学习能力,但其性能易受超参数选择影响且更易过拟合;而在缺乏条件标签进行超参数调优的实际应用中,Harmony,作为结构更简单、鲁棒性更强的线性方法代表,可能更具实用优势,尤其适用于跨研究、跨平台的数据整合与分类任务。
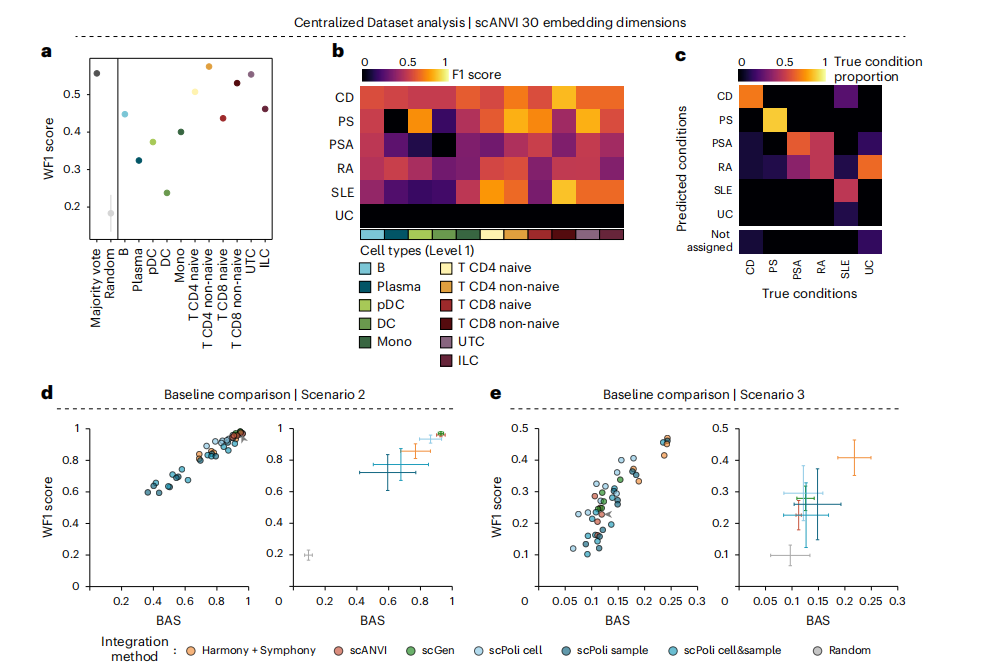
图8 利用中心化数据集上对比scANVI与其他分类算法
本研究构建了一个基于PBMC免疫细胞单细胞图谱的炎症性疾病综合分析框架,通过整合梯度提升决策树与SHapley可加性解释方法,系统识别了具有疾病判别功能的关键基因,并建立了基于深度生成模型的患者分类系统。该模型在已知研究内部验证中表现出优异性能,但在跨研究数据中泛化能力显著下降,经中心化数据集分析证实技术批次效应是主要限制因素,通过标准化数据策略可部分提升模型稳定性。
当前框架仍存在多重局限:样本主要来源于欧洲血统人群,需扩展至多祖先队列以提升全球代表性;模型尚未经过前瞻性多中心临床验证,其临床实用性待进一步证实;循环免疫细胞与组织驻留细胞的分子关联机制仍需深入解析,这对理解外周血检测的生物学基础至关重要。这些局限提示,该技术目前仍处于转化医学的探索阶段。
为实现临床转化,未来需建立标准化实验流程与质量控制体系以减少批次效应,并通过两种并行策略推进:一是构建严格控制变量的中心化高质量数据集,二是开发能够整合多中心异质数据的基础模型。这两种途径将共同推动建立能够抵抗技术变异、具有更强泛化能力的疾病诊断新系统,最终实现基于免疫细胞的精准医疗范式革新。
艾斯基因
艾斯基因创建于2016年,是一家专注于生命健康领域的国家高新技术企业和专精特新企业,经过多年的发展已形成完善稳定的多组学产品矩阵。Bulk表观组学包括DNA甲基化(EM-seq、WGBS、RRBS、935K芯片/测序、靶向甲基化TBS等)、DNA羟甲基化(5hmC-Seal、ACE-seq、hMeDIP-seq等)、IP体系(ChIP-seq、m6A-seq、RIP-seq等)、Tn5体系(ATAC-seq、CUT&Tag等);另外提供单细胞组学(10x单细胞(核)转录组)、蛋白组学(血浆深度蛋白组学DIA、Illumina IPP)、代谢组(非靶代谢、非靶脂质组学及血脂亚组分)、暴露组等组学产品服务,我们可从实验设计—样本处理—生信分析—数据挖掘应用全链条参与您的方案。
ACEGEN入选美国《生命科学评论》杂志评选“亚太地区2025年最佳表观遗传多组学技术方案供应商”。
有相关课题研究的老师欢迎联系我们!